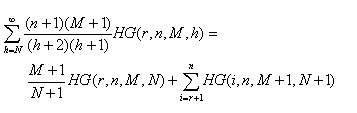水産資源解析の大部分は「データ解析」であり,昔から数理統計学的手法が多用されてきました。かつ
ては多大な労力を必要としたこれらの手法も,現在ではパソコンと表集計ソフトの普及によって手軽に使
用できるようになり,研究の主体も数理生態学的手法や生態系モデル等に移行しつつあります。その一方
で,情報量規準などの新しい概念や手法も積極的に導入されてきていますが,その中の「ベイズ統計学」
について検討してみます。東京大学出版会より出版された「実践としての統計学」(2000)という教科書
のp19に「アメリカでは半分近くが「ベイズ統計学派」「ベイジアン」Bayesianである。学問に国境があ
る例である」と書かれていて,今後は日本においてもベイズ統計学が流行ると思われるからです。
ベイズ統計学とは?
ベイズ統計学は「ベイズの定理」だけを用いる,単純で強力な統計学です。この定理は数学的に正しく
,「事前確率」が既知の場合にはまったく問題ありません。しかし通常の統計的な問題では事前確率が未
知の場合がほとんどです。大数学者であるラプラスは,根拠薄弱のためにいくつかの相互に排反な事象に
等確率を与える「理由不十分の原理」を用いて,ベイズ統計学を積極的に使用しました。これについては
岩波文庫「確率の哲学的試論」(1997)などで読むことができます。
このような事前確率は主観に左右されるため,これを徹底的に排除して近代統計学の基礎を固めようと
したのがフィッシャーでした。しかしながらフィッシャーの提唱したフィデューシャル確率はほとんど支
持されず,最終的に「帰無仮説」を用いて事前確率を完全に追放したのはネイマンとピアソンです。通常
の統計学はこのネイマン・ピアソン流の立場をとっていて,ベイジアンに対して頻度論者(frequentist)
と呼びますが,ベイズ統計学に対して「伝統的統計学」と呼ぶことにします。
現代のベイズ統計学はラプラス時代のような単純なものではなく,もっと複雑・高度化されています。
主なものは階層モデルと経験(empirical)ベイズで,前者はモデルの未知パラメータの事前分布に含まれ
る超パラメータにさらに無情報事前分布を仮定したもの,後者は超パラメータの事前分布は未知と考え,
それを観測データから最尤法で推定するものです。
このように事前分布に柔軟性を持たせただけでなく,
マルコフ連鎖・モンテカルロ(MCMC)法のような実用的な計算手法の導入によって急速に普及してきていま
す。しかしながら具体的なモデルやデータについて伝統的統計学との比較はほとんど行われていません。
ここでは水産資源学における個体数推定の基本的手法である標識再捕法において,両者を比較して,その
有効性を検討してみます。
ピーターセン法の確率モデル
標識再捕法の基本モデルは1回放流1回再捕で,水産資源分野ではピーターセン(Petersen)法と呼ばれて
います。N尾の魚のうちM尾に標識を付けて,十分に混合させた後でn尾再捕したところr尾に標識が付いて
いたとします。このときM,n,rの値からNを推定する方法です。点推定はN=Mn/rとなって簡単ですが,区
間推定は意外と面倒です。確率モデルが必要となるからです。
伝統的統計学ではrの確率だけを用います。
ピーターセン法の確率モデルは超幾何分布:HG(r,n,M,N)=C(M,r)C(N-M,n-r)/C(N,n)
で,C(a,b)=a!/b!(a-b)!は組合せ数です。これは壺実験における非復元抽出モデルと同一です。NとMがn
とrと比較して十分に大きな場合には,標識率p=M/Nはほとんど変化しないので,
2項分布:Bi(r,n,p)=C(n,r)pr(1-p)n-r
に近似できます。これは壺実験における復元抽出モデルと同一です。超幾何分布は扱いにくいので,まず
2項分布で検討してみます。nとrからpを区間推定し,N=M/pによってNの値に変換するわけです。実はベ
イズ自身が行ったのは,この2項分布におけるpの区間推定でした。統計や確率の教科書に載っているベイ
ズの定理は後にラプラスが一般化したものです。
伝統的統計学における区間推定
先ほど述べたように伝統的統計学ではrの確率分布しか用いません。本当はパラメータであるpの確率分
布を考えた方が楽なのですが,それはベイズ統計学の立場です。したがって伝統的統計学では「もしpの
真値がp0であったならば」という仮定(帰無仮説)を立てて推論します。
つまり数学的には「確率を用いた
背理法」です。そのため95%信頼区間というときの「95%」はパラメータのpではなくて,rについての確
率を意味しています。ですから,たとえrが1回だけの試行で得られたデータだったとしても「何回か試行
した場合に,各試行で得られたデータrを用いて計算したパラメータpの推定区間のうち,100回に95回く
らいがpの真値を含んでいる」という解釈になるわけです。伝統的統計学の立場を頻度論者と呼ぶ理由が
納得できたと思います。
以上のような説明よりも,実際に図で示した方が理解が早いでしょう。図は横軸にr=0~100を,縦軸
にp=0~1をとったもので,n=100とした横方向の2項分布が上(z軸方向)に無数に乗っているとイメ
ージしてください。右上がりの対角線はp=r/nです。各2項分布においてrの95%区間が計算できるので
,上側の曲線はその下限を結んだもの,下側の曲線は上限を結んだものです。図のようにpの真値がp0の
とき,rの95%区間はa~bとなります。r0はこの95%区間内の点で,この点においてpを区間推定すると
図の2本の曲線内の縦棒(実線)となり,これは常に真値p0を含んでいます。逆に区間外の点であるr1やr2
では信頼区間の縦棒は真値を含んでいません。このように信頼区間が真値を含む確率は95%ですが,こ
れはあくまでも横方向のrについての確率で,縦方向のpについての確率ではありません。つまり伝統的
統計学では「横のものを縦に見ている」わけです。

図.2項分布におけるpの区間推定(n=100の場合)
|
|---|
ベイズ統計学における区間推定
しかし一方で,縦方向の確率も計算してみたくなるのが自然な願望です。縦方向の確率つまりパラメ
ータの確率を計算して直接に区間推定を行うのがベイズ統計学です。実際に縦方向の確率の総和を計算
してみると,部分積分の公式から簡単に,

が求まります。rは0~nまでの(n+1)個の値をとり,この平面全体の総和は1だから,納得のいく値です。
これよりパラメータpの事前分布を一様分布:
Pprior(p)=1
と仮定すると,ベイズの定理からpの事後分布はPpost(p)=(n+1)Bi(r,n,p)
となります。これからpの95%確率区間が直接求まるわけです。以上のようにベイズ統計学と伝統的統
計学とでは計算方法も95%の意味もまったく異なっています。
問題は「pの事前分布を一様分布と仮定してよいか」ということです。ラプラスのように理由不十分
の原理によってというのでは,本当に理由不十分でしょう。実はこの場合には次の公式が成立します。

この式はrの上側確率とpの事後分布の下側確率がほぼ一致することを意味しています。したがってpの
事前確率を一様分布と仮定して区間推定した場合には,伝統的統計学の解とほとんど一致するわけです
。さらに事前分布が一様分布なので,この事後分布のモード(最頻値)は伝統的統計学における最尤解と
一致します。
2項分布のpの区間推定は統計学におけるもっとも基本的な問題のひとつで,非常に多くの論文が現在
でも書かれています。たとえば新数学事典(大阪書籍,初版)のp695には,ここの図をさまざまなnの値
に対応させた一般的な図が載っています。ベイズ統計学においても一様分布以外の多くの事前分布が提
唱されています。当然ですが,そのような事後分布の解は伝統的統計学の解とは異なります。そのよう
な手法を用いる場合には,十分な注意が必要でしょう。
超幾何分布のNの区間推定
比較のため超幾何分布のNの区間推定を検討してみましょう。伝統的統計学では帰無仮説:N=N0を立
てて,2項分布の場合とまったく同様に行います。一方,ベイズ統計学においてNの事前分布を一様分布
と仮定して計算すると,今までのものとまったく異なる結果が出てきます。p=M/Nなので,pとNは反比
例の関係にあるため,pが一様分布する場合にはNは一様分布しないからです。そこで天下り式で申し訳
ないのですが,Nの事前分布を
Pprior(N)=(M+1)/(N+2)(N+1)
と仮定すると,部分和分公式を用いて,

という今までと同様の式が得られます。これよりNの事後分布は,
Ppost(N)=(n+1)(M+1)HG(r,n,M,N)/(N+2)(N+1)
となります。さらに
という公式が成立します。この式はrの上側確率とNの事後分布の上側確率がほぼ一致することを意味し
ています。先の総和公式は10年以上も前に得ていましたが,この式は今年になって得ることができまし
た。部分和分公式は2通りあるため,以前用いなかった方を用いたら簡単に求まったのですが,そのこと
に気づかなかったのです。
ところで事後分布Ppost(N)を通常の離散分布とみなすと,2項分布の場合の事後分布Ppost(p)は連続分
布であるため,両者の整合性が悪くなり,たとえばモードが一致しません。
整合性を高めるにはPpost(N)
を,高さHG(r,n,M,N),幅Pprior(N)のヒストグラムとみなす必要があります。こうすれば両者のモード
は一致します。したがってこの事例では通常のベイズ統計学と事後分布の解釈が異なります。このように
事前分布が一様分布でない場合には注意が必要だと思います。
実用的な区間推定方法
ピーターセン法の区間推定についても多くの手法が提唱されていますが,中には確率モデル自体が誤っ
ているものも見受けられます。
いくつかの数値例について検討してみた結果,実用性が高く精度も十分な
方法は,伝統的統計学において2項分布をさらに正規分布に近似し,半整数補正する方法:
であることが分かりました。ここで複号逆順に注意してください。複号同順となっている論文が多いので
すが,それだとかえって信頼区間が長くなってしまいます。半整数補正というのは離散分布である2項分
布を連続分布である正規分布で近似するため,正規分布においてa~bの区間を「a-0.5~b+0.5」の区間
に補正するものです。図においてpの上限は横方向の2項分布におけるrの下限,pの下限はrの上限ですか
ら複号逆順になるわけです。
ベイズ統計学は有効か?
統計学は実学の代表ですから,使いやすく,しかも結果が常識的な感覚に合致するものでないと有効と
は言えません。事前分布を一様分布と仮定する古典的なベイズ統計学は,横のものを縦に見る伝統的統計
学と違って,パラメータの確率分布を直接に知りたいという自然な願望に合致するものでした。今回比較
した単純な事例ではベイズ統計学はそれなりに有効でしたが,伝統的統計学の手法よりも優れているとは
言えませんでした。しかしながら伝統的統計学が適用しにくい複雑な事例では,ベイズ統計学の方が有効
となる可能性もあります。
もっとも,最近流行のベイズ統計学の手法は「屋上屋を架す」ような印象を受
けますから,伝統的統計学との比較や数値実験を十分に行った上で用いるべきでしょう。
ここではpの推定に話を限定しましたが,nを推定する場合にも同じような関係が成立します。
それについての話や具体的な数値例,およびその他の関係式の詳細などについては水産総合研究センター研究報告
2号(2002)に「枠どり法とPetersen法の区間推定における伝統的統計学とベイズ統計学との比較」として
掲載予定ですので,ご参照ください。
なお最近のベイズ統計学については岸野洋久「生のデータを料理す
る」日本評論社(1999),丹後俊郎「統計モデル入門」朝倉書店(2000)を参考にしました。以前は面倒
だった確率分布の計算は,表集計ソフトで簡単にできるのですが,それについては岩崎学「統計的データ
解析のレシピ」日本評論社(2000)が参考になるでしょう。
(生物生態部数理生態研究室長)
 目次へ
目次へ
中央水研日本語ホームページへ